かくびーが東大の生物情報科学科の学生になったのは、大学二年生の八月末日、夏休み半ばのことだった。
別にもしドラ読んだことないのでこれ以上はやめておきます。
さて、発端は以下のツイートです。
そういえば、もし今度越境する知性会議あれば"Stable Diffusion を基礎から理解してみた"やってみたいな
— かくびー (@cakkby2) 2022年11月12日
もちろん発表の形でもよかったのですが、せっかくなのでブログの方で連載する形で進めてみようかと思いました。
こちらの記事に、どういう論文を読み進めていけば StableDiffusion など拡散モデルの理解が可能になるかが紹介されていました。
そこで、実際に画像系の深層学習にはあまり詳しくない自分が、これらの論文を読んだうえで、文字に起こしておけば、将来何かの役に立つかもしれないということです。
まずは自分の現状・前提知識についてまとめておきます。
- 機械学習については、情報系に興味がある一般の学生レベルの教養はある。誤差逆伝播法、確率的勾配降下法など深層学習の基本原理や、SVM, HMMなどやや昔の手法については一通り学んだことがある。BERT, AlphaFold2 など生物情報科学に関連する深層学習系は少し学んでいる。
- 画像系の機械学習についてはそこまで詳しくはない。ただし、kaggle の semantic segmentation のコンペティションに少し手を出したことがあるため、Mask R-CNN などの一部の技術は見たことがある。
- 機械学習関連の本として、以下に目を通したことはある(理解しているとは限らない)。PRML(変分ベイズあたりまで), ゼロつく3, カーネル多変量解析, 機械学習プロフェッショナルシリーズのいくらか(深層学習第2版, 強化学習, 機械学習のための連続最適化, など), 渡辺ベイズ, ...
- 実際に深層学習をガッツリ回したことは大してない。深層学習系の論文をちゃんと通読するのも初めて。
ちょっと深層学習にも興味がある一般的な学生くらいの感じだと思ってもらえると良いかと思います。画像系については実際はCNN, GAN以上のことは大して知らないので、基礎的なところから見ていきます。もちろん初心者なので、間違ったことを言っているかもしれないです。意見やコメントは歓迎です。
それでは早速、有名な Geoffrey E. Hinton 先生の AlexNet と呼ばれるものから見てみようと思います。基礎となる論文は現在の技術の基盤となる発見があるようなので、じっくり見てみましょう。
AlexNet (2012)
元論文:https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
画像認識では、2010年から ILSVRC (ImageNet Large Scale Visual Recognition Challenge) と呼ばれるコンペティションが開かれるようになったらしく、100万越えの高解像度画像に対し、1000 個のクラスに分類するという、大規模なものとなっています。そして、名前にある ImageNet も、1500万超の画像に22000ほどのクラスがつけられた大規模画像データベースです。
これほど多くの(リアルな)画像のデータセットが手に入ったのは(当時は)最近のことらしく、AlexNet はそのコンペティションで既存のモデルの精度を大幅に上回る最先端の(state-of-the-art, SOTA)ものとなりました。
AlexNet は 256×256 に固定された大きさの入力画像を 5 つの畳み込み層と 3 つの全結合層のニューラルネットワークによって 1000 個のラベルへの予測値に変換します。画像は、大きさを揃えてRGBの値を中心化する以外は特に前処理していないようです。
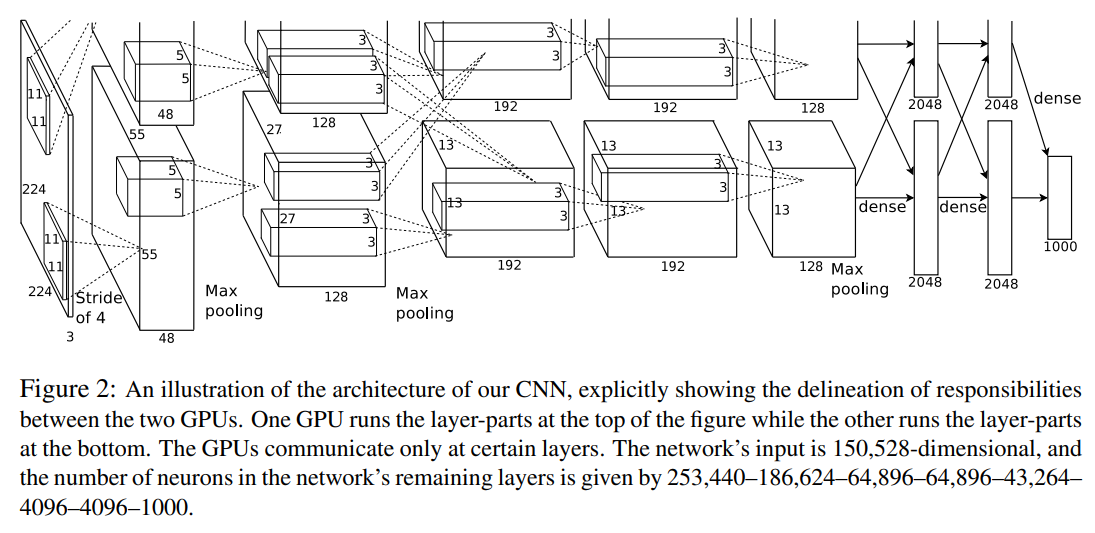
この論文のアーキテクチャは、Neocognitron (Fukushima, 2003) や LeNet (LeCun et al., 1999) など既存の CNN のものと大差ないようですが、それらで発生してしまう各種の問題を解決するためのテクニックがいくらか導入されました。
ReLU
それまで、ニューラルネットワークに用いる非線形な活性化関数としては、
tanh関数 :
シグモイド関数 :
などが広く用いられてきました。これらの関数は、微分の値がほとんどの場合で1を下回ります。誤差逆伝播のアルゴリズムは微分の値を上流へと掛け算の形で還元していくため、深層学習のように何層分も掛け算をするうちに、伝播するはずの誤差がほとんど0になってしまうという問題があります(勾配消失問題)。
一方、ReLU (Xavier et al., 2011) と呼ばれる関数は
ReLU関数 :
0より大きな入力はそのまま線形に出力するものの、0以下は0へと整流するものとなっており、微分の値は入力が正のとき1のままとなります。これにより、勾配の消失が抑えられ、深層の学習にも耐えることが出来るようになったため、今回採用されたようです。
実際、tanhを用いた場合と比べて、ReLUを用いた場合は学習が何倍も速くなり、大規模な学習データにも対応しやすくなったと報告しています。
Dropout
機械学習では、アンサンブル学習のように、複数のモデルの良いとこどりをすると性能が向上しやすいことが知られています。しかし、大規模な深層学習のネットワークは一回の学習に長い時間がかかるので、複数のモデルを実際に求めるのは効率的ではありません。
Dropout (Hinton et al., 2014) はそれを近似できる手法のひとつで、学習の際、入力のたびにニューロンの出力を確率的に 0 にします。出力が 0 になることは、下流に情報が伝わらなくなるだけでなく、上流へと誤差を逆伝播することもなくなるため、毎回の学習で異なる構造の、しかし重みは共通したニューラルネットワークが利用されます。これは複数のモデルを使った学習と似た効果を発揮するため、汎化性能が上がるようです。
Dropoutは全結合層の最初の2層に適用し、実際に適用する前は酷かった過学習を抑えることに成功したそうです。
Data Augmentation
アーキテクチャ以外に、入力データの処理も過学習を抑える効果を持ちます。入力画像を平行移動させたり、左右反転させることで、入力のかさ増しと汎化(不変性の獲得)が可能となります。ほかに、RGBの画素値を(ImageNetの画像全体に対するPCAから得られた)固有値・固有ベクトルに沿ってランダムに弄ることで、色合いの多少異なる自然な画像を生成して利用しています。
また、テストの際にもこのような Data Augmentation をした入力の平均を考えたようです。
その他のテクニック
さらに、汎化性能を高めるために、いくつかのテクニックを利用しています。
この論文では、新しく Local Response Normalization とよばれる正規化手法を開発しています。座標 にカーネル
が畳み込み処理を行った出力(activity)
に対し、同じ位置に適用された"隣接する"他のカーネルの値を用いて正規化処理を行います。
なお、ここで言う neighbors とは、カーネル の前後
個のカーネルを指すもので、少しややこしいですが式にすると
となります。 この仕組みは、実際のニューロン(や動物の発生のメカニズムなど)にも見られる側方抑制と呼ばれるものにインスパイアされたものらしいです。側方抑制は、周りの近接する細胞同士がお互いの活性を邪魔する物質を流しあうことで、真に強い活性をもつ細胞のみが一人勝ちするようなメカニズムで、おそらく不必要なニューロンの活性が抑えられることで汎化しやすくなることが狙いのようです。
次に、pooling層の処理方法も従来のものから少し変えているようです。CNN における pooling 処理とは、周辺のピクセルの情報を max やら average やらで要約することで位置の揺らぎに対応し、過学習を抑える目的で行われます。具体的には、 だけ離れたピクセルごとに、周囲
個のピクセルの情報を要約するのですが、今まで
として要約するピクセルの情報がオーバーラップしないようにしていたものを、あえて
としてオーバーラップさせることで、わずかに過学習の抑制効果が上昇するとしています(実際どうなのかはわからないですが)。
学習結果
学習ではバッチサイズ128でモーメント付き確率的勾配降下法を行い、90サイクルを6日間かけて実行しています。ILSVRC-2012 の結果は2位とかなりの差をつけて圧勝しており、エラー率は 16 % 程となっていました。今となってはあまり低くないですが、当時としては凄い結果なのだと思います。

このように、AlexNet はそれまで過学習や上手く学習できない問題のあったCNNが現実的なデータセットで活躍できるようになったブレイクスルーとなる研究でした。以後、VGGNetなど後続のモデルの基礎として利用されているようです。
アーキテクチャのPyTorchコード
最後に AlexNet に対応する(疑似)PyTorch コードを示そうと思います。
# x --> feature --> avgpool --> flatten --> classifier --> y y = classifier(flatten(avgpool(feature(x)))) feature = Sequential( Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4), # 224×224×3 --> 55×55×96 ReLU(), MaxPool2d(kernel_size=3, stride=2), # 55×55×96 --> 27×27×96 Conv2d(96, 256, kernel_size=5, padding=2), # 27×27×96 --> 27×27×256 ReLU(), MaxPool2d(kernel_size=3, stride=2), # 27×27×256 --> 13×13×256 Conv2d(256, 384, kernel_size=3, padding=1), # 13×13×256 --> 13×13×384 ReLU(), Conv2d(384, 256, kernel_size=3, padding=1), # 13×13×384 --> 13×13×256 ReLU(), Conv2d(256, 256, kernel_size=3, padding=1), # 13×13×256 --> 13×13×256 ReLU(), MaxPool2d(kernel_size=3, stride=2), # 13×13×256 --> 6×6×256 ) avgpool = AdaptiveAvgPool2d((6, 6)) classifier = Sequential( Linear(256 * 6 * 6, 4096), ReLU(), Linear(4096, 4096), ReLU(), Linear(4096, cls_num), )
AlexNetでは全結合層の入力次元が固定(幅=6, 高さ=6, チャネル数=256)となるため、最初の入力画像の大きさを 幅=224, 高さ=224 の固定サイズとする必要があります。
(参考)
github.com
次回は、画像のセグメンテーションや生成・変換に利用される U-Net について書こうと思います。